Work optimization memory#54
Conversation
Change method work to streaming style work
improve collecting allBrowsers stats
improve Date parsing
user key (RubyProf Callgrind)
improve collection of allBrowsers
remove double file_line split
|
data_large: |
 spajic
left a comment
spajic
left a comment
There was a problem hiding this comment.
Хорошая работа, здорово, что попробовали разные профилировщики 👍
|
|
||
| ## Feedback-Loop | ||
| Для того, чтобы иметь возможность быстро проверять гипотезы я выстроил эффективный `feedback-loop`, который позволил мне получать обратную связь по эффективности сделанных изменений за *время, которое у вас получилось* | ||
| Для того, чтобы иметь возможность быстро проверять гипотезы я выстроил эффективный `feedback-loop`, который позволил мне получать обратную связь по эффективности сделанных изменений за 40 с (до оптимизации). Возможно время выполнения пока достаточно большое, но предыдущий опыт показал, что первые оптимизации довольно быстро уменьшают время, что в первой задаче привело к тому, что стало просто неочевидно - сказались изменения или нет. Либо я что-то делаю не так. |
There was a problem hiding this comment.
В районе минуты - вполне ок.
| Показатели: MEMORY USAGE: 170 MB Work time: 40.490744165999786. | ||
| Попробовал запустить метод с опросом по памяти в конце обработки каждой строки. Максимальное значение, что увидел, примерное такое же (169) +/- погрешность. Но до 10000 строк значение составляли до 80 МВ, и только после выросло выше 100. Либо данные так скомпонованы, либо что-то накапливается. В любом случае, на первом этапе этот размер данных полагаю подходящим. | ||
| Все измерения на ноуте с питанием от сети, CPU в режиме perfomance. | ||
| update: далее быстро выяснил, что запуск с профилировщиком и таким объемом данных это нерабочая схема. Для метрики можно использовать такой пакет, но для профилирования возьму 3250 строк. |
There was a problem hiding this comment.
Да, профилировщик сильно замедляет работу. Особенно если это трассирующий профилировщик, как ruby-prof.
stackprof в этом плане полегче, а через rbspy можно даже на продовый процесс посмотреть.
|
|
||
| Итог: переписал в потоковом стиле. Выбрал вариант с записью в один файл, то есть информация по пользователю пишется сразу после обработки его "блока сессий". | ||
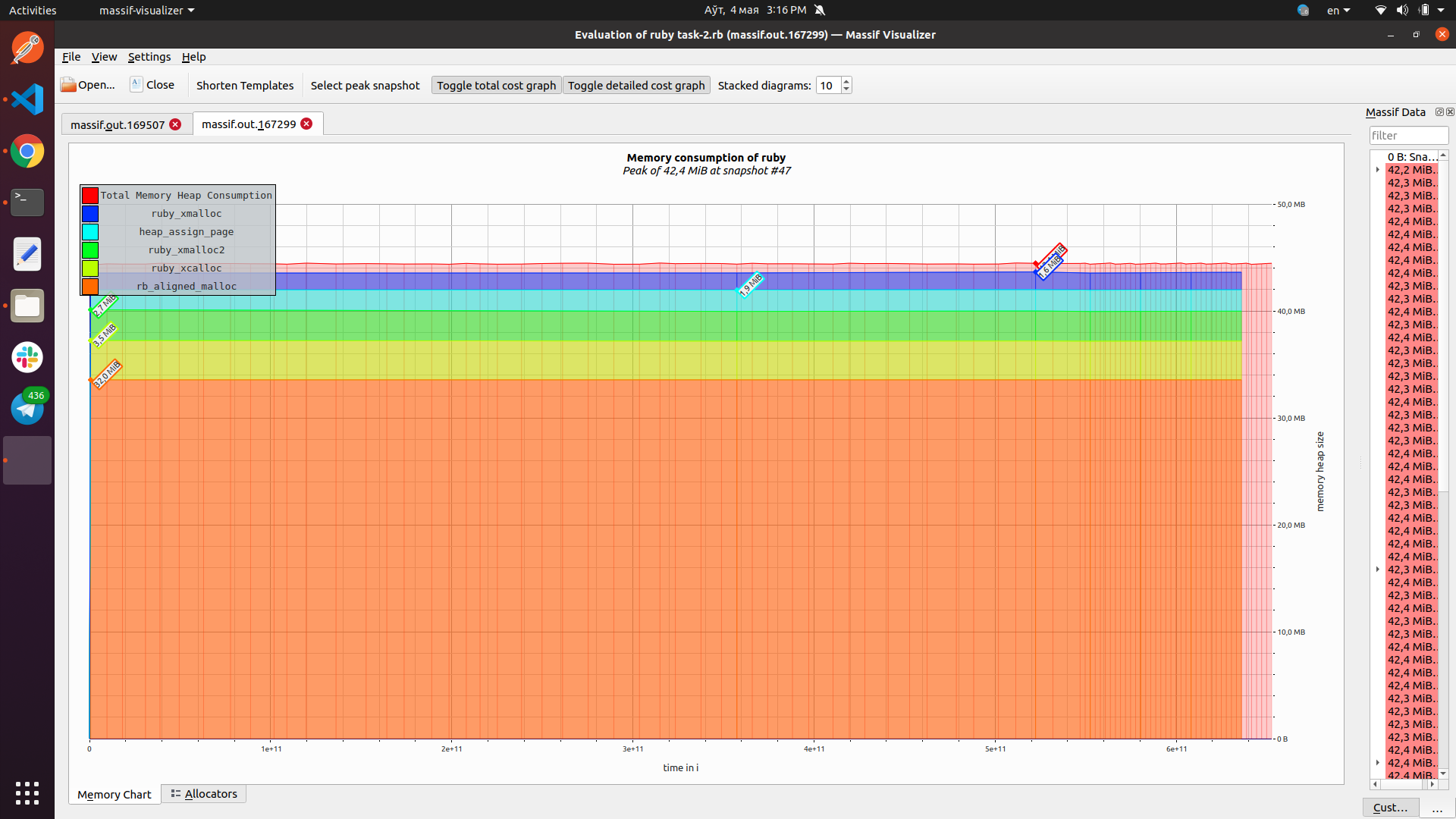
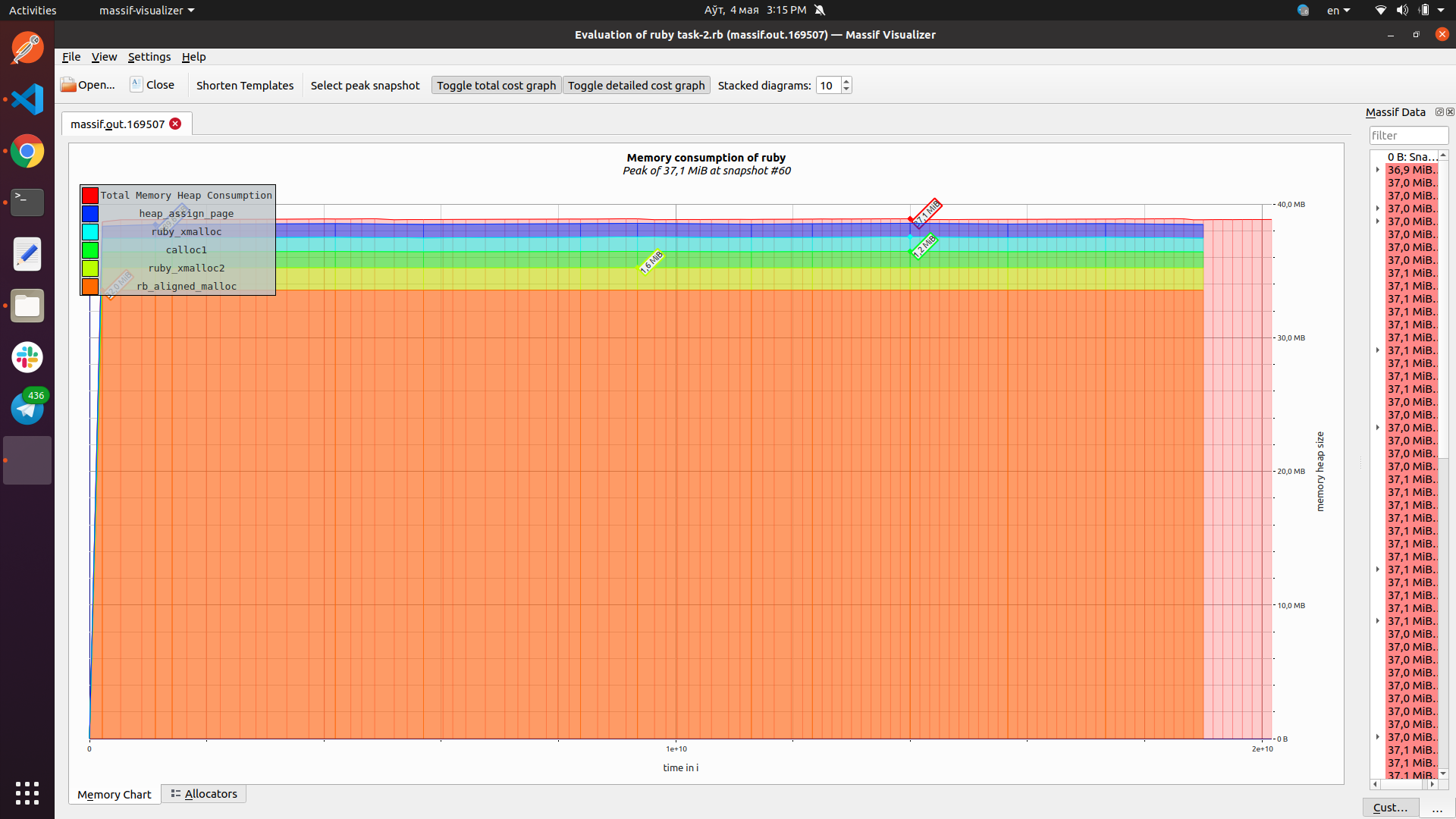
| Теперь метод в работе занимает 30-32 МБ, это проверял на 3250, 16250, 32500 и 100_000(проверял это запросом по памяти в каждой строке ()при 16250), но надо подтвердить в `valgrind massif visualizer`). | ||
| Выявилась проблема: "Полные тезки". На 100_000 итоговый json начал выдавать предупреждения о проблеме "Duplicate object key". Дело в том, что пользователи с одинаковыми именем и фамилией генерируют одинаковый ключ. Надо бы добавить id к ключу, чтоб решить эту проблему. Пример: `user,4011,Rico,Waneta,13`, `user,10412,Rico,Waneta,13` |
There was a problem hiding this comment.
Есть такая штука, можно пренебречь в этом задании
| Graph и Stack тоже указывают на парсинг дат как следующую точку роста. | ||
|
|
||
| - Даты в отчет записываются в виде строки из сортированных дат, чтобы сохранять возможность сортировки в ходе анализа сессий одного пользователя буду хранить даты в массиве. Сортировку и преобразование в строку выделю в одтельный метод и буду вызывать перед записью в файл. | ||
| - метрика осталась на прежнем уровне. У меня появилось подозрение, что я уже укладываюсь в бюджет. Проверил это с помощью valgrind, так и есть, программа выходит на уровень 43 МБ и дальше идет ровно. Хоть и есть мантра №1, но мой главный профит не в оптимизации метода, а в опробовании профайлеров. Так что еще пару итераций я сделаю |
There was a problem hiding this comment.
Плюсую, главное добавить себе в арсенал новые умения.
| users = [] | ||
| sessions = [] | ||
| def prepare_dates_for_report_json(report, user, user_key) | ||
| report['usersStats'][user_key]['dates'] = report['usersStats'][user_key]['dates'].sort.reverse.map!(&:iso8601) |
There was a problem hiding this comment.
С датами можно ничего не делать, это подвох
метод sort создаёт новый массив
метод reverse тоже создаёт новый массив
|
|
||
| # Collect total stats | ||
| report['totalSessions'] += 1 | ||
| uniqueBrowsers += [session['browser']] if uniqueBrowsers.all? { |b| b != session['browser'] } |
There was a problem hiding this comment.
Создаём лишние массивы
Лучше uniqueBrowsers << session['browser']
Или можно использовать класс Set для сбора уникальных браузеров
uniqueBrowsers.all? не эффективно, требует полного перебора uniqueBrowsers - опять-таки решается использованием Set
| uniqueBrowsers += [session['browser']] if uniqueBrowsers.all? { |b| b != session['browser'] } | ||
| report['uniqueBrowsersCount'] = uniqueBrowsers.count | ||
|
|
||
| report['allBrowsers'] << session['browser'].upcase unless report['allBrowsers'].include?(session['browser'].upcase) |
There was a problem hiding this comment.
include? тоже в худшем случае требует полного перебора
|
|
||
| # Браузеры пользователя через запятую | ||
| collect_stats_from_user(report, user, user_key) do |user| | ||
| user.sessions_stats['browsers'] = (user.sessions_stats['browsers'].split(',').map(&:strip) << session['browser'].upcase).sort.join(', ') |
There was a problem hiding this comment.
map, sort создают новые массивы
memory_profilerruby-profв режимеFlat;ruby-profв режимеGraph;ruby-profв режимеCallStack;ruby-profв режимеCallTreec визуализацией вQCachegrind;stackprof;flamegraphс помощьюstackprofи визуализировать его вspeedscope.app;valgrind massif visualierи включить скриншот в описание вашегоPR;