LST: Remove matrix caps for MDs using Precompute#256
LST: Remove matrix caps for MDs using Precompute#256
Conversation
|
run-ci: [all, hlt] |
|
The PR was built and ran successfully in standalone mode running on CPU. Here are some of the comparison plots.
The full set of validation and comparison plots can be found here. Here is a timing comparison: |
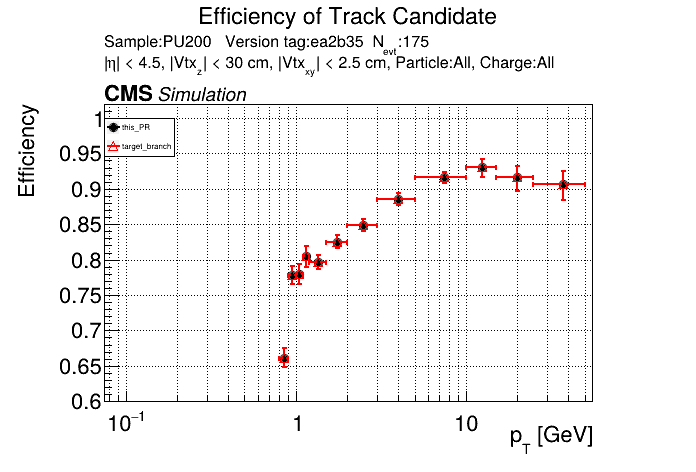
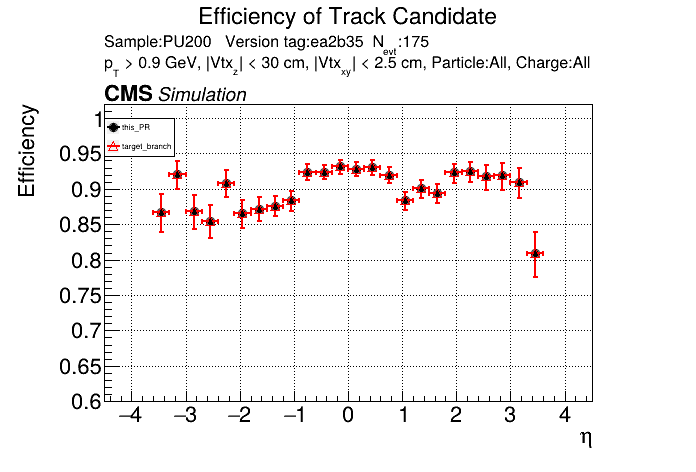
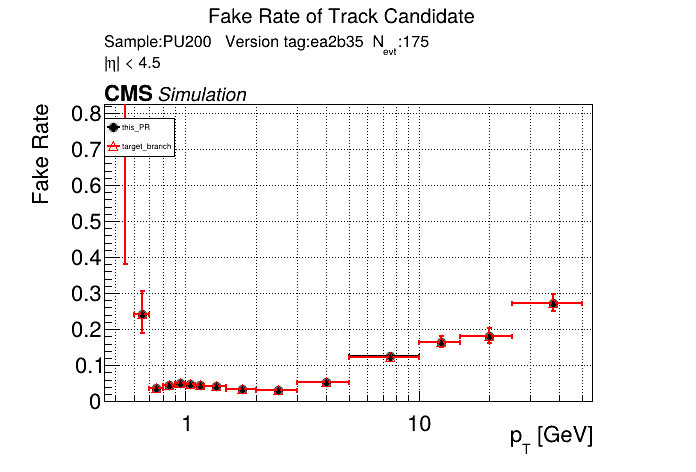
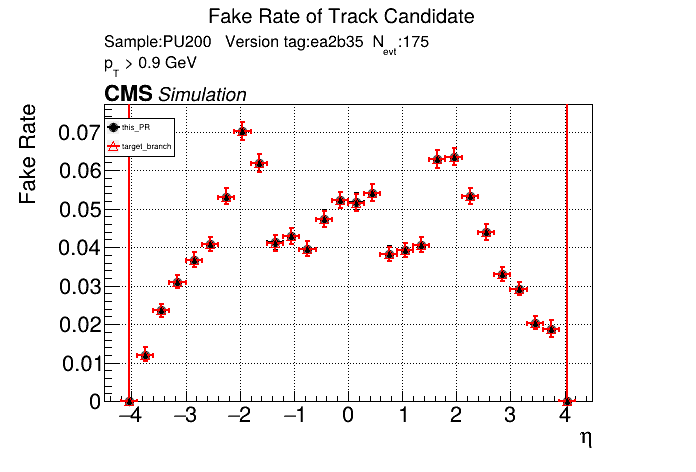
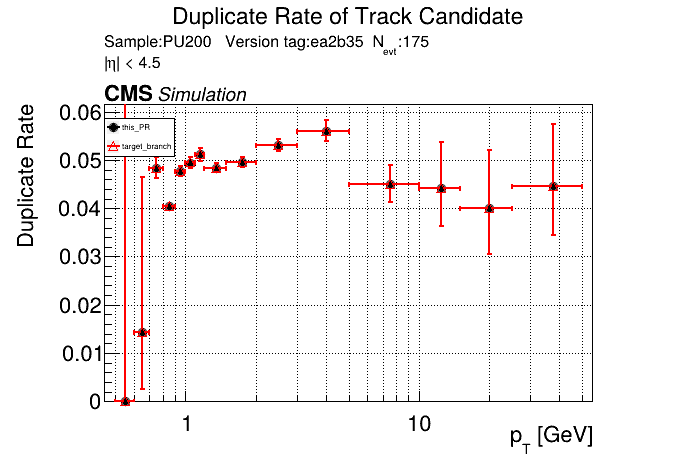
|
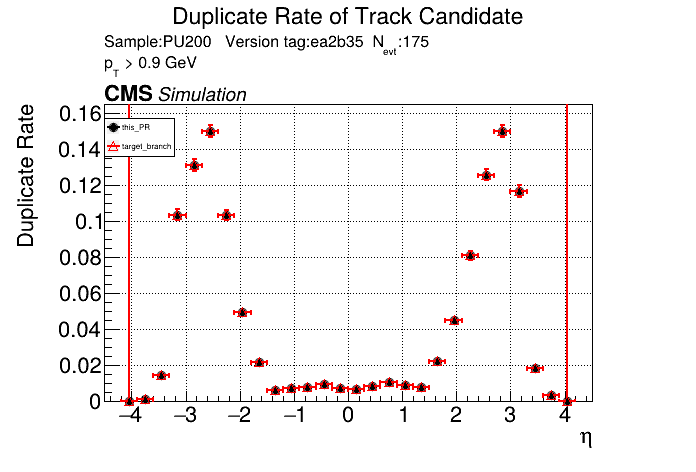
The PR was built and ran successfully with HLT setup running on CPU (procModifiers = ). Here are some plots. HLT General Plots
The full set of validation and comparison plots can be found here. |
|
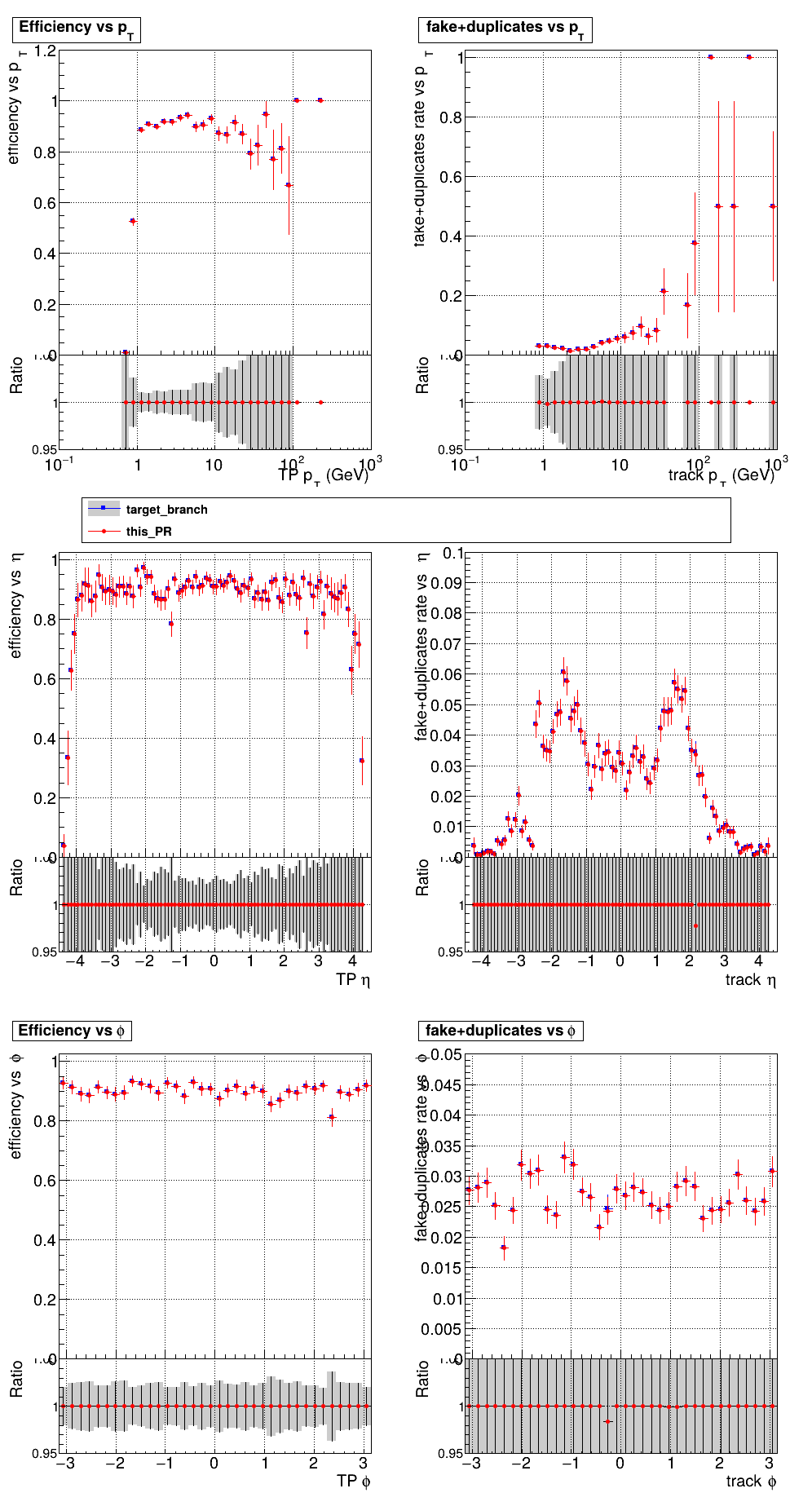
The PR was built and ran successfully with CMSSW running on CPU. Here are some plots. OOTB All Tracks
The full set of validation and comparison plots can be found here. |
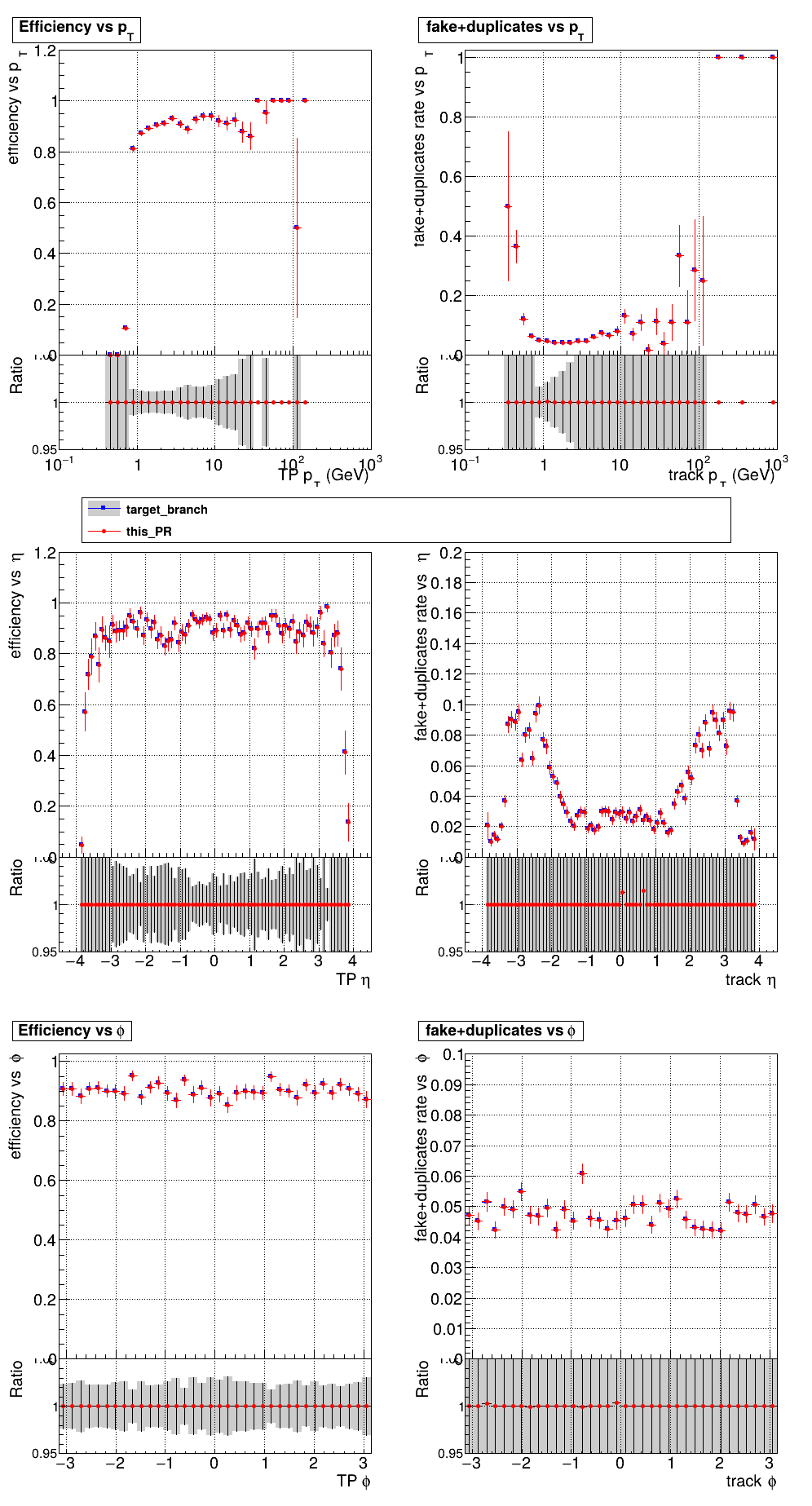

Why did the pLS time change? (or is it not a pLS column? recall that the header text is missing a T4 kernel; I guess T4 is now under the TC, if I recall the rough timing cost correctly) |
Just compiler weirdness or effects from multi-stream. The pLS time on lnx4555 CPU single-stream fluctuates randomly between 360 and 316 even when I don't touch it. I don't think you would see this in HLT since the main kernel there (accounts for almost all pLS time) is the pLS dedup which is turned off. |
|
in #245 the MD time went down from 323.6 to 90, now up from 90 to 163. Still a net gain. From a quick glance the PR looks good to go. |
|
@slava77 PR description updated |
Thank you. |
Most LST objects (segments, triplets, quintuplets, ...) size their buffers from an upper-bound estimate computed in an initial counting pass before object creation (see previous PR's here: cms-sw#50157, cms-sw#48698, cms-sw#47232). Memory for LST mini-doublets (two hits in a given module) are currently allocated using the minimum of a loose dynamic estimate (n hits lower sensor x n hits upper sensor) and static caps based on detector region. These static caps help reduce overallocation from the loose dynamic estimate but can cause truncation for high-occupancy events and have to be re-tuned by hand when hit selections or pT cuts change. This PR replaces these static caps with a precomputed exact-count: We first compute the number of mini-doublets that will be created in a counting pass and then allocate an exact-size buffer to store them. This eliminates possible truncation and reduces the memory allocated for mini-doublets for a small increase in overall timing. Mini-doublet memory drops from 31.4 MB to 7.4 MB on average (~22% decrease in total memory/event for LST) for a ~7% increase in LST time/event.